AWS storage for Kubernetes performance
Do you want some form of persistence on Kubernetes? What are your options? How does it perform? In this post I go over some options on AWS, but it can be used for other platforms aswell.
Step 1: Don't use volumes if you can
I think I have to say this. Try to not get into the state (pun intended) of having to worry about stateful applications on Kubernetes. It's just annoying and even though there are options, it's not that cool to figure these things out. Storage is hard. Storage for a cloud-native orchestration tool containing diverse workloads is even harder.
Best-case you work with stateless applications, cloud-native, and based on the '12 factor principle' (https://12factor.net/)
So if your use-case is some wacko old-school application that needs to share a volume between 10 pods and does madness read/writes to it.. Then seriously stop and don't use Kubernetes in the first place. Not using Kubernetes does not solve the actual problem, but at least you don't have to figure your NFS problems out on another complex system.
However, I do believe there are use-cases.
Identifing your use-case
I believe there are 4 options;
- Storage for "applications"
- Storage for "media" and cloud-native solutions
- "I have legacy-stuff and I'm just doing something or I have no idea what I'm doing - storage".
- The "I actually have a decent use-case and I'm using this - storage"
So basically these are also the availible products.
- EBS, just good storage in both IOPS and throughput. It can be mounted to a single system. In fact, you can just see this as a regular HDD (or better yet SSD).
- Object storage, S3. Great to host "media" on it. Either you use it as CDN or do something smart in your application with it.
- EFS, an NFS file share on steroids. Number 3 & 4 on the use-cases use this.
Let's just recap this a bit. We have storage that is basically the standard disk you have in your PC. Then we have two options for sharing files between multiple systems. It's that simple. So why is storage difficult?
Expecting and wanting too much
Now we have this application and "I have to share these files between 100 systems". Best-case you can use S3 to give your systems access to the files. The applications load this data or serve it (or even as CDN). Yet what happens is that often applications start to do the processing. It's going to read the file, write others, change files and do a gazillion other actions. The question is "how".
There is nothing wrong with "downloading" the data from S3, do some processing, and uploading it back. It does not "hurt" other systems and the processing can take place on your local storage (or EBS in that case).
Yet if you have an EFS/NFS mount, applications tend to do that processing ON that share. Continuously doing those read/writes. It's just not made for that. NFS can work if you periodically call a file. It just does not work if you write the logs of 100 systems to 1 single file on a share. For that you just ship it into a logging solution that can run cloud-native and you are set.
Difference between EFS and S3?
It might look that EFS and S3 are somewhat similar. I do think they share the same use-case but the implementation is different. We can go into much more details, but I try to keep it high-level here: With EFS we have a file system, with S3 we have a RESTful API. We mount the EFS volume and with S3 we can programmatically get our objects.
This is also why EFS is a thing. Not all applications are made for an object-store. It tends to be that legacy wants a simple file system. This is "fine". However, it's keener to cause performance issues because it's easier to do things that it should not be done on a file share.
What is a valid use-case for EFS or NFS-like systems?
- Probably not your use-case.
- Not for applications
- Unlikely for Kubernetes workloads
The problem is that people tend to go for EFS because it's "the" solution that can mount a single volume to many systems. So instead of making your application cloud-native, 12factor-style. They just mount a share and "yolo".
Yes, it would work. Yes, it might be "good" for you now. However, there are so many pitfalls and issues that can and will happen. If you do something wrong in your application or the workload is increasing, you have the chance to completely fail on your storage. It's then to slow, it has hiccups, it locks - you will cry.
Using the right tool for the job
So we can define a somewhat solid use-case for the various storage solutions. Let's say I'm running Prometheus. It needs storage but I'm also taking a more cloud-native approach by implementing either Cortex or Thanos.
What happens is that Prometheus will process data and store this, but for a limited amount. Every 2 hours my data gets uploaded to an object-store. That's it. For the future chain of 'logic', the object store data is used.
In this case, I will use EBS volumes for Prometheus and let Cortex/Thanos do the rest on S3. I even can make this setup high available without the need to have a file share between the Prometheuses. The data just gets shipped twice to the object store and de-duplicated later on.
Neat.
The single flaw in EBS
However, there is one thing that EBS cannot do. It's not able to mount cross-zone. If I have a machine in zone A and I want EBS; the EBS volume will get created in zone A and it will be locked there. I simply cannot unmount and mount that volume to an instance in zone B.
I could "solve" this by running, for example, Prometheus in two different zones. If there is a zone outage, at least one instance is still up. The other instance will not be able to reschedule in Kubernetes because it simply cannot find a node that is in the correct zone for the volume.
Multi-zone clusters and EBS
The neat thing about Kubernetes is that you provide a workload (I.e. pods) and they get scheduled over the nodes you have. When we have a cluster that is using 3 AZ's (availability zones) - we do however have a little problem.
If we use EBS, that pod is dead-locked to a specific set of nodes in a specific AZ. If the zone goes down, it won't be able to schedule that pod. It will search for space in a node, which can mount the volume. Yet there are no nodes because the AZ is down.
If you use EBS and you want to be HA (high availability), you will need to have a minimum of 2 replicas with a zone anti-affinity. I.e. replica's get scheduled in different zones. If the zone goes down, 1 replica is down, yet the other will keep working.
The trade-off with EBS and multi-zone Kubernetes
If you want to be HA, you will have to force a minimum of 2 replicas on your workloads that require a volume like EBS. This has multiple downsides:
- You will need twice the compute power (CPU/mem)
- You will need a big overcommitment to be able to schedule everything
Let's say I run 10 pods that have a volume. 4 live in zone A, 4 in zone B, and 2 in zone C. Things are fine, but now I have to scale my cluster because my workload increases, and I need more memory. So I add extra nodes. If I want to support the 4 pods that live in Zone A, I need to add n*3 nodes, because of AZ's.
I.e I want to add 2 nodes in zone A, I need to add 2*3, 6 nodes. 2 in A, 2 in B, and 2 nodes in zone C. Unless I'm going to specifically add nodes to a certain zone. Yet this beats the purpose of Kubernetes and perhaps poses more problems later on when a zone outage happens.
But why not use EFS then?
So EFS can mount in every AZ. Yet why I should not use it? That's using the right tool for the job. Yes, it can mount everywhere, but it's not made for the workload that I do. I do know that AWS advertise on IOPS and throughput for EFS, but frankly, it's not suitable for applications or EBS-like volumes. Don't take my word for it, let's test it.
Testing it
So I've created an EC2 instance for the sake of testing. It's a bit easier than setting up various storage controllers/drivers.
The instance I used was a 2 CPU, 4 GB memory instance. I then mounted 3 volumes.
- 1 EBS volume of 30GB
- 1 EFS General Purpose volume
- 1 EFS Max I/O volume with a Provisioned Throughput of 4MB/s
I used the tool FIO with the following test-case:
1[global]
2name=fio-rand-RW
3filename=fio-rand-RW
4rw=randrw
5rwmixread=60
6rwmixwrite=40
7bs=4K
8direct=0
9numjobs=4
10time_based
11runtime=900
12
13[file1]
14size=10G
15ioengine=libaio
16iodepth=16
I believe this somewhat pushes the system for the behaviour that you can expect from an application that is trying quite hard.
EBS
1file1: (g=0): rw=randrw, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=libaio, iodepth=16
2...
3fio-3.1
4Starting 4 processes
5file1: Laying out IO file (1 file / 10240MiB)
6Jobs: 4 (f=4): [m(4)][100.0%][r=18.3MiB/s,w=12.2MiB/s][r=4677,w=3122 IOPS][eta 00m:00s]
7file1: (groupid=0, jobs=1): err= 0: pid=20470: Sat Feb 6 20:53:59 2021
8 read: IOPS=562, BW=2251KiB/s (2305kB/s)(1979MiB/900001msec)
9 slat (usec): min=2, max=178266, avg=1088.46, stdev=1565.14
10 clat (usec): min=28, max=262712, avg=16074.01, stdev=15871.56
11 lat (usec): min=398, max=269008, avg=17163.72, stdev=16870.85
12 clat percentiles (msec):
13 | 1.00th=[ 4], 5.00th=[ 5], 10.00th=[ 6], 20.00th=[ 7],
14 | 30.00th=[ 8], 40.00th=[ 9], 50.00th=[ 10], 60.00th=[ 11],
15 | 70.00th=[ 13], 80.00th=[ 24], 90.00th=[ 41], 95.00th=[ 55],
16 | 99.00th=[ 73], 99.50th=[ 80], 99.90th=[ 91], 99.95th=[ 96],
17 | 99.99th=[ 106]
18 bw ( KiB/s): min= 496, max= 5648, per=24.95%, avg=2251.02, stdev=1615.05, samples=1800
19 iops : min= 124, max= 1412, avg=562.72, stdev=403.76, samples=1800
20 write: IOPS=375, BW=1503KiB/s (1539kB/s)(1321MiB/900001msec)
21 slat (usec): min=3, max=96415, avg=1013.27, stdev=1747.81
22 clat (usec): min=5, max=258974, avg=15844.44, stdev=15836.98
23 lat (usec): min=23, max=262640, avg=16858.86, stdev=16776.30
24 clat percentiles (msec):
25 | 1.00th=[ 4], 5.00th=[ 5], 10.00th=[ 6], 20.00th=[ 7],
26 | 30.00th=[ 8], 40.00th=[ 9], 50.00th=[ 10], 60.00th=[ 11],
27 | 70.00th=[ 13], 80.00th=[ 23], 90.00th=[ 41], 95.00th=[ 54],
28 | 99.00th=[ 73], 99.50th=[ 80], 99.90th=[ 91], 99.95th=[ 95],
29 | 99.99th=[ 106]
30 bw ( KiB/s): min= 288, max= 3624, per=24.94%, avg=1503.06, stdev=1083.55, samples=1800
31 iops : min= 72, max= 906, avg=375.73, stdev=270.89, samples=1800
32 lat (usec) : 10=0.01%, 50=0.01%, 250=0.01%, 500=0.01%, 750=0.01%
33 lat (usec) : 1000=0.01%
34 lat (msec) : 2=0.07%, 4=2.11%, 10=52.53%, 20=23.86%, 50=15.10%
35 lat (msec) : 100=6.29%, 250=0.02%, 500=0.01%
36 cpu : usr=0.57%, sys=3.36%, ctx=954242, majf=1, minf=11
37 IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=100.0%, 32=0.0%, >=64=0.0%
38 submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
39 complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.1%, 32=0.0%, 64=0.0%, >=64=0.0%
40 issued rwt: total=506556,338245,0, short=0,0,0, dropped=0,0,0
41 latency : target=0, window=0, percentile=100.00%, depth=16
42file1: (groupid=0, jobs=1): err= 0: pid=20471: Sat Feb 6 20:53:59 2021
43 read: IOPS=564, BW=2259KiB/s (2314kB/s)(1986MiB/900001msec)
44 slat (usec): min=2, max=96180, avg=1087.73, stdev=1547.74
45 clat (usec): min=27, max=250965, avg=16000.04, stdev=15779.10
46 lat (usec): min=50, max=257360, avg=17089.02, stdev=16775.86
47 clat percentiles (msec):
48 | 1.00th=[ 4], 5.00th=[ 5], 10.00th=[ 6], 20.00th=[ 7],
49 | 30.00th=[ 8], 40.00th=[ 9], 50.00th=[ 10], 60.00th=[ 11],
50 | 70.00th=[ 13], 80.00th=[ 23], 90.00th=[ 41], 95.00th=[ 54],
51 | 99.00th=[ 73], 99.50th=[ 80], 99.90th=[ 91], 99.95th=[ 96],
52 | 99.99th=[ 107]
53 bw ( KiB/s): min= 496, max= 5458, per=25.06%, avg=2261.26, stdev=1622.41, samples=1800
54 iops : min= 124, max= 1364, avg=565.18, stdev=405.62, samples=1800
55 write: IOPS=377, BW=1512KiB/s (1548kB/s)(1329MiB/900001msec)
56 slat (usec): min=3, max=174374, avg=1002.89, stdev=1748.38
57 clat (usec): min=5, max=246378, avg=15780.95, stdev=15731.99
58 lat (usec): min=19, max=252531, avg=16784.97, stdev=16661.97
59 clat percentiles (msec):
60 | 1.00th=[ 4], 5.00th=[ 5], 10.00th=[ 6], 20.00th=[ 7],
61 | 30.00th=[ 8], 40.00th=[ 9], 50.00th=[ 10], 60.00th=[ 11],
62 | 70.00th=[ 13], 80.00th=[ 23], 90.00th=[ 41], 95.00th=[ 54],
63 | 99.00th=[ 73], 99.50th=[ 80], 99.90th=[ 91], 99.95th=[ 96],
64 | 99.99th=[ 106]
65 bw ( KiB/s): min= 336, max= 3912, per=25.10%, avg=1512.91, stdev=1090.43, samples=1800
66 iops : min= 84, max= 978, avg=378.11, stdev=272.58, samples=1800
67 lat (usec) : 10=0.01%, 50=0.01%, 100=0.01%, 500=0.01%, 750=0.01%
68 lat (usec) : 1000=0.01%
69 lat (msec) : 2=0.08%, 4=2.20%, 10=52.85%, 20=23.41%, 50=15.30%
70 lat (msec) : 100=6.13%, 250=0.03%, 500=0.01%
71 cpu : usr=0.53%, sys=3.40%, ctx=955398, majf=0, minf=13
72 IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=100.0%, 32=0.0%, >=64=0.0%
73 submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
74 complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.1%, 32=0.0%, 64=0.0%, >=64=0.0%
75 issued rwt: total=508376,340134,0, short=0,0,0, dropped=0,0,0
76 latency : target=0, window=0, percentile=100.00%, depth=16
77file1: (groupid=0, jobs=1): err= 0: pid=20472: Sat Feb 6 20:53:59 2021
78 read: IOPS=563, BW=2255KiB/s (2309kB/s)(1982MiB/900001msec)
79 slat (usec): min=2, max=36556, avg=1085.50, stdev=1544.38
80 clat (usec): min=142, max=239522, avg=16009.40, stdev=15792.14
81 lat (usec): min=147, max=242281, avg=17096.17, stdev=16787.27
82 clat percentiles (msec):
83 | 1.00th=[ 4], 5.00th=[ 5], 10.00th=[ 6], 20.00th=[ 7],
84 | 30.00th=[ 8], 40.00th=[ 9], 50.00th=[ 10], 60.00th=[ 11],
85 | 70.00th=[ 13], 80.00th=[ 23], 90.00th=[ 41], 95.00th=[ 54],
86 | 99.00th=[ 73], 99.50th=[ 81], 99.90th=[ 93], 99.95th=[ 97],
87 | 99.99th=[ 110]
88 bw ( KiB/s): min= 424, max= 5680, per=24.99%, avg=2255.00, stdev=1619.12, samples=1800
89 iops : min= 106, max= 1420, avg=563.72, stdev=404.78, samples=1800
90 write: IOPS=376, BW=1507KiB/s (1543kB/s)(1325MiB/900001msec)
91 slat (usec): min=3, max=180505, avg=1012.37, stdev=1765.62
92 clat (usec): min=5, max=242263, avg=15859.64, stdev=15842.96
93 lat (usec): min=135, max=243047, avg=16873.17, stdev=16782.22
94 clat percentiles (msec):
95 | 1.00th=[ 4], 5.00th=[ 5], 10.00th=[ 6], 20.00th=[ 7],
96 | 30.00th=[ 8], 40.00th=[ 9], 50.00th=[ 10], 60.00th=[ 11],
97 | 70.00th=[ 13], 80.00th=[ 23], 90.00th=[ 41], 95.00th=[ 54],
98 | 99.00th=[ 73], 99.50th=[ 80], 99.90th=[ 93], 99.95th=[ 97],
99 | 99.99th=[ 109]
100 bw ( KiB/s): min= 328, max= 3608, per=25.00%, avg=1506.78, stdev=1080.48, samples=1800
101 iops : min= 82, max= 902, avg=376.66, stdev=270.12, samples=1800
102 lat (usec) : 10=0.01%, 250=0.01%, 500=0.01%, 750=0.01%, 1000=0.01%
103 lat (msec) : 2=0.07%, 4=2.12%, 10=52.70%, 20=23.70%, 50=15.21%
104 lat (msec) : 100=6.16%, 250=0.04%
105 cpu : usr=0.67%, sys=3.24%, ctx=956670, majf=1, minf=11
106 IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=100.0%, 32=0.0%, >=64=0.0%
107 submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
108 complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.1%, 32=0.0%, 64=0.0%, >=64=0.0%
109 issued rwt: total=507450,339079,0, short=0,0,0, dropped=0,0,0
110 latency : target=0, window=0, percentile=100.00%, depth=16
111file1: (groupid=0, jobs=1): err= 0: pid=20473: Sat Feb 6 20:53:59 2021
112 read: IOPS=564, BW=2256KiB/s (2310kB/s)(1983MiB/900001msec)
113 slat (usec): min=2, max=174351, avg=1086.38, stdev=1564.66
114 clat (usec): min=5, max=224279, avg=16001.65, stdev=15727.92
115 lat (usec): min=392, max=227137, avg=17089.26, stdev=16724.56
116 clat percentiles (msec):
117 | 1.00th=[ 4], 5.00th=[ 5], 10.00th=[ 6], 20.00th=[ 7],
118 | 30.00th=[ 8], 40.00th=[ 9], 50.00th=[ 10], 60.00th=[ 11],
119 | 70.00th=[ 13], 80.00th=[ 23], 90.00th=[ 41], 95.00th=[ 54],
120 | 99.00th=[ 73], 99.50th=[ 80], 99.90th=[ 91], 99.95th=[ 96],
121 | 99.99th=[ 107]
122 bw ( KiB/s): min= 480, max= 5434, per=25.04%, avg=2259.20, stdev=1624.18, samples=1800
123 iops : min= 120, max= 1358, avg=564.59, stdev=406.06, samples=1800
124 write: IOPS=376, BW=1506KiB/s (1542kB/s)(1323MiB/900001msec)
125 slat (usec): min=3, max=100681, avg=1011.28, stdev=1735.27
126 clat (usec): min=395, max=224278, avg=15876.79, stdev=15810.02
127 lat (usec): min=400, max=224290, avg=16889.20, stdev=16740.12
128 clat percentiles (msec):
129 | 1.00th=[ 4], 5.00th=[ 5], 10.00th=[ 6], 20.00th=[ 7],
130 | 30.00th=[ 8], 40.00th=[ 9], 50.00th=[ 10], 60.00th=[ 11],
131 | 70.00th=[ 13], 80.00th=[ 24], 90.00th=[ 41], 95.00th=[ 54],
132 | 99.00th=[ 73], 99.50th=[ 79], 99.90th=[ 91], 99.95th=[ 95],
133 | 99.99th=[ 107]
134 bw ( KiB/s): min= 248, max= 3632, per=25.01%, avg=1507.46, stdev=1079.29, samples=1800
135 iops : min= 62, max= 908, avg=376.69, stdev=269.78, samples=1800
136 lat (usec) : 10=0.01%, 500=0.01%, 750=0.01%, 1000=0.01%
137 lat (msec) : 2=0.08%, 4=2.10%, 10=52.72%, 20=23.61%, 50=15.29%
138 lat (msec) : 100=6.17%, 250=0.02%
139 cpu : usr=0.62%, sys=3.29%, ctx=956696, majf=0, minf=13
140 IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=100.0%, 32=0.0%, >=64=0.0%
141 submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
142 complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.1%, 32=0.0%, 64=0.0%, >=64=0.0%
143 issued rwt: total=507663,338748,0, short=0,0,0, dropped=0,0,0
144 latency : target=0, window=0, percentile=100.00%, depth=16
145
146Run status group 0 (all jobs):
147 READ: bw=9022KiB/s (9239kB/s), 2251KiB/s-2259KiB/s (2305kB/s-2314kB/s), io=7930MiB (8315MB), run=900001-900001msec
148 WRITE: bw=6028KiB/s (6172kB/s), 1503KiB/s-1512KiB/s (1539kB/s-1548kB/s), io=5298MiB (5555MB), run=900001-900001msec
149
150Disk stats (read/write):
151 xvdb: ios=1511378/1245594, merge=0/22, ticks=1525247/4155320, in_queue=2205008, util=99.50%
EFS General Purpose
1file1: (g=0): rw=randrw, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=libaio, iodepth=16
2...
3fio-3.1
4Starting 4 processes
5file1: Laying out IO file (1 file / 10240MiB)
6fio: native_fallocate call failed: Operation not supported
7Jobs: 4 (f=4): [f(4)][100.0%][r=0KiB/s,w=0KiB/s][r=0,w=0 IOPS][eta 00m:00s]
8file1: (groupid=0, jobs=1): err= 0: pid=20508: Sat Feb 6 21:24:36 2021
9 read: IOPS=73, BW=294KiB/s (301kB/s)(258MiB/900031msec)
10 slat (usec): min=3, max=11172k, avg=8297.13, stdev=72921.08
11 clat (msec): min=10, max=13528, avg=120.65, stdev=397.06
12 lat (msec): min=14, max=13568, avg=128.95, stdev=415.57
13 clat percentiles (msec):
14 | 1.00th=[ 36], 5.00th=[ 44], 10.00th=[ 48], 20.00th=[ 54],
15 | 30.00th=[ 58], 40.00th=[ 62], 50.00th=[ 66], 60.00th=[ 70],
16 | 70.00th=[ 75], 80.00th=[ 82], 90.00th=[ 94], 95.00th=[ 115],
17 | 99.00th=[ 1452], 99.50th=[ 1670], 99.90th=[ 4111], 99.95th=[ 9597],
18 | 99.99th=[13087]
19 bw ( KiB/s): min= 7, max= 760, per=27.72%, avg=325.15, stdev=256.13, samples=1626
20 iops : min= 1, max= 190, avg=81.21, stdev=64.04, samples=1626
21 write: IOPS=48, BW=195KiB/s (200kB/s)(172MiB/900031msec)
22 slat (usec): min=4, max=12026k, avg=7973.68, stdev=97935.35
23 clat (usec): min=9, max=13646k, avg=125701.44, stdev=456961.73
24 lat (msec): min=12, max=13864, avg=133.68, stdev=478.26
25 clat percentiles (msec):
26 | 1.00th=[ 37], 5.00th=[ 44], 10.00th=[ 49], 20.00th=[ 55],
27 | 30.00th=[ 59], 40.00th=[ 63], 50.00th=[ 66], 60.00th=[ 70],
28 | 70.00th=[ 75], 80.00th=[ 83], 90.00th=[ 95], 95.00th=[ 117],
29 | 99.00th=[ 1485], 99.50th=[ 1687], 99.90th=[ 9194], 99.95th=[12416],
30 | 99.99th=[13489]
31 bw ( KiB/s): min= 7, max= 598, per=28.13%, avg=220.00, stdev=170.06, samples=1596
32 iops : min= 1, max= 149, avg=54.91, stdev=42.52, samples=1596
33 lat (usec) : 10=0.01%
34 lat (msec) : 20=0.02%, 50=12.95%, 100=79.19%, 250=3.90%, 500=0.19%
35 lat (msec) : 750=0.25%, 1000=0.68%, 2000=2.61%, >=2000=0.21%
36 cpu : usr=0.12%, sys=0.67%, ctx=146755, majf=0, minf=8
37 IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=100.0%, 32=0.0%, >=64=0.0%
38 submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
39 complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.1%, 32=0.0%, 64=0.0%, >=64=0.0%
40 issued rwt: total=66133,43920,0, short=0,0,0, dropped=0,0,0
41 latency : target=0, window=0, percentile=100.00%, depth=16
42file1: (groupid=0, jobs=1): err= 0: pid=20509: Sat Feb 6 21:24:36 2021
43 read: IOPS=73, BW=293KiB/s (300kB/s)(257MiB/900030msec)
44 slat (usec): min=3, max=12061k, avg=8374.49, stdev=82376.05
45 clat (usec): min=12, max=13553k, avg=122864.34, stdev=420015.71
46 lat (msec): min=18, max=13627, avg=131.24, stdev=439.43
47 clat percentiles (msec):
48 | 1.00th=[ 36], 5.00th=[ 44], 10.00th=[ 49], 20.00th=[ 54],
49 | 30.00th=[ 58], 40.00th=[ 62], 50.00th=[ 66], 60.00th=[ 70],
50 | 70.00th=[ 75], 80.00th=[ 82], 90.00th=[ 94], 95.00th=[ 117],
51 | 99.00th=[ 1469], 99.50th=[ 1670], 99.90th=[ 6812], 99.95th=[ 9866],
52 | 99.99th=[13355]
53 bw ( KiB/s): min= 7, max= 808, per=27.44%, avg=321.84, stdev=255.40, samples=1638
54 iops : min= 1, max= 202, avg=80.42, stdev=63.81, samples=1638
55 write: IOPS=48, BW=195KiB/s (200kB/s)(171MiB/900030msec)
56 slat (usec): min=4, max=9339.9k, avg=7911.09, stdev=87069.71
57 clat (msec): min=17, max=13737, avg=123.18, stdev=431.11
58 lat (msec): min=17, max=13817, avg=131.09, stdev=451.21
59 clat percentiles (msec):
60 | 1.00th=[ 37], 5.00th=[ 45], 10.00th=[ 49], 20.00th=[ 55],
61 | 30.00th=[ 59], 40.00th=[ 63], 50.00th=[ 67], 60.00th=[ 71],
62 | 70.00th=[ 77], 80.00th=[ 83], 90.00th=[ 95], 95.00th=[ 118],
63 | 99.00th=[ 1485], 99.50th=[ 1703], 99.90th=[ 7148], 99.95th=[10134],
64 | 99.99th=[13489]
65 bw ( KiB/s): min= 8, max= 536, per=28.49%, avg=222.78, stdev=169.51, samples=1576
66 iops : min= 2, max= 134, avg=55.69, stdev=42.38, samples=1576
67 lat (usec) : 20=0.01%
68 lat (msec) : 20=0.01%, 50=12.47%, 100=79.68%, 250=3.92%, 500=0.17%
69 lat (msec) : 750=0.28%, 1000=0.65%, 2000=2.58%, >=2000=0.26%
70 cpu : usr=0.13%, sys=0.66%, ctx=146681, majf=0, minf=8
71 IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=100.0%, 32=0.0%, >=64=0.0%
72 submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
73 complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.1%, 32=0.0%, 64=0.0%, >=64=0.0%
74 issued rwt: total=65869,43900,0, short=0,0,0, dropped=0,0,0
75 latency : target=0, window=0, percentile=100.00%, depth=16
76file1: (groupid=0, jobs=1): err= 0: pid=20510: Sat Feb 6 21:24:36 2021
77 read: IOPS=73, BW=293KiB/s (300kB/s)(258MiB/900016msec)
78 slat (usec): min=3, max=8465.3k, avg=7962.96, stdev=39572.21
79 clat (usec): min=12, max=13775k, avg=123922.26, stdev=437645.82
80 lat (msec): min=18, max=13883, avg=131.89, stdev=449.52
81 clat percentiles (msec):
82 | 1.00th=[ 36], 5.00th=[ 44], 10.00th=[ 48], 20.00th=[ 54],
83 | 30.00th=[ 58], 40.00th=[ 62], 50.00th=[ 66], 60.00th=[ 70],
84 | 70.00th=[ 75], 80.00th=[ 82], 90.00th=[ 94], 95.00th=[ 117],
85 | 99.00th=[ 1435], 99.50th=[ 1636], 99.90th=[ 8490], 99.95th=[ 9866],
86 | 99.99th=[13489]
87 bw ( KiB/s): min= 8, max= 784, per=27.57%, avg=323.41, stdev=255.67, samples=1633
88 iops : min= 2, max= 196, avg=80.80, stdev=63.86, samples=1633
89 write: IOPS=49, BW=196KiB/s (201kB/s)(172MiB/900016msec)
90 slat (usec): min=4, max=11945k, avg=8458.35, stdev=123591.78
91 clat (msec): min=11, max=13759, avg=120.56, stdev=395.14
92 lat (msec): min=14, max=13775, avg=129.02, stdev=426.79
93 clat percentiles (msec):
94 | 1.00th=[ 36], 5.00th=[ 45], 10.00th=[ 49], 20.00th=[ 54],
95 | 30.00th=[ 58], 40.00th=[ 63], 50.00th=[ 66], 60.00th=[ 71],
96 | 70.00th=[ 75], 80.00th=[ 83], 90.00th=[ 95], 95.00th=[ 117],
97 | 99.00th=[ 1435], 99.50th=[ 1603], 99.90th=[ 3809], 99.95th=[ 9463],
98 | 99.99th=[13489]
99 bw ( KiB/s): min= 8, max= 609, per=28.59%, avg=223.54, stdev=170.40, samples=1580
100 iops : min= 2, max= 152, avg=55.88, stdev=42.60, samples=1580
101 lat (usec) : 20=0.01%
102 lat (msec) : 20=0.01%, 50=12.88%, 100=79.25%, 250=3.86%, 500=0.19%
103 lat (msec) : 750=0.26%, 1000=0.65%, 2000=2.68%, >=2000=0.21%
104 cpu : usr=0.13%, sys=0.64%, ctx=146791, majf=0, minf=9
105 IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=100.0%, 32=0.0%, >=64=0.0%
106 submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
107 complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.1%, 32=0.0%, 64=0.0%, >=64=0.0%
108 issued rwt: total=65983,44155,0, short=0,0,0, dropped=0,0,0
109 latency : target=0, window=0, percentile=100.00%, depth=16
110file1: (groupid=0, jobs=1): err= 0: pid=20511: Sat Feb 6 21:24:36 2021
111 read: IOPS=73, BW=293KiB/s (300kB/s)(258MiB/900016msec)
112 slat (usec): min=3, max=11536k, avg=8309.89, stdev=78193.81
113 clat (msec): min=13, max=13882, avg=121.87, stdev=424.10
114 lat (msec): min=13, max=13887, avg=130.18, stdev=442.50
115 clat percentiles (msec):
116 | 1.00th=[ 36], 5.00th=[ 44], 10.00th=[ 48], 20.00th=[ 54],
117 | 30.00th=[ 58], 40.00th=[ 62], 50.00th=[ 66], 60.00th=[ 70],
118 | 70.00th=[ 75], 80.00th=[ 82], 90.00th=[ 94], 95.00th=[ 117],
119 | 99.00th=[ 1469], 99.50th=[ 1720], 99.90th=[ 6812], 99.95th=[10268],
120 | 99.99th=[13355]
121 bw ( KiB/s): min= 8, max= 753, per=27.64%, avg=324.17, stdev=255.93, samples=1630
122 iops : min= 2, max= 188, avg=80.94, stdev=63.88, samples=1630
123 write: IOPS=48, BW=196KiB/s (201kB/s)(172MiB/900016msec)
124 slat (usec): min=4, max=12026k, avg=7952.12, stdev=92106.64
125 clat (usec): min=50, max=13783k, avg=123812.27, stdev=421857.04
126 lat (msec): min=14, max=13892, avg=131.77, stdev=443.19
127 clat percentiles (msec):
128 | 1.00th=[ 36], 5.00th=[ 44], 10.00th=[ 48], 20.00th=[ 54],
129 | 30.00th=[ 58], 40.00th=[ 63], 50.00th=[ 67], 60.00th=[ 71],
130 | 70.00th=[ 75], 80.00th=[ 83], 90.00th=[ 95], 95.00th=[ 118],
131 | 99.00th=[ 1502], 99.50th=[ 1687], 99.90th=[ 6477], 99.95th=[ 9731],
132 | 99.99th=[13355]
133 bw ( KiB/s): min= 8, max= 569, per=28.35%, avg=221.71, stdev=171.23, samples=1591
134 iops : min= 2, max= 142, avg=55.42, stdev=42.80, samples=1591
135 lat (usec) : 100=0.01%
136 lat (msec) : 20=0.01%, 50=13.29%, 100=78.87%, 250=3.89%, 500=0.17%
137 lat (msec) : 750=0.24%, 1000=0.69%, 2000=2.61%, >=2000=0.22%
138 cpu : usr=0.12%, sys=0.65%, ctx=146572, majf=0, minf=11
139 IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=100.0%, 32=0.0%, >=64=0.0%
140 submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
141 complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.1%, 32=0.0%, 64=0.0%, >=64=0.0%
142 issued rwt: total=65972,44098,0, short=0,0,0, dropped=0,0,0
143 latency : target=0, window=0, percentile=100.00%, depth=16
144
145Run status group 0 (all jobs):
146 READ: bw=1173KiB/s (1201kB/s), 293KiB/s-294KiB/s (300kB/s-301kB/s), io=1031MiB (1081MB), run=900016-900031msec
147 WRITE: bw=783KiB/s (801kB/s), 195KiB/s-196KiB/s (200kB/s-201kB/s), io=688MiB (721MB), run=900016-900031msec
EFS Max I/O
1file1: (g=0): rw=randrw, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=libaio, iodepth=16
2...
3fio-3.1
4Starting 4 processes
5file1: Laying out IO file (1 file / 10240MiB)
6fio: native_fallocate call failed: Operation not supported
7
8Jobs: 4 (f=4): [f(4)][100.0%][r=0KiB/s,w=0KiB/s][r=0,w=0 IOPS][eta 00m:00s]
9file1: (groupid=0, jobs=1): err= 0: pid=20617: Sat Feb 6 22:33:00 2021
10 read: IOPS=44, BW=177KiB/s (181kB/s)(155MiB/900008msec)
11 slat (usec): min=3, max=1025.5k, avg=14004.16, stdev=55094.99
12 clat (msec): min=11, max=15599, avg=203.57, stdev=723.39
13 lat (msec): min=14, max=16181, avg=217.57, stdev=767.70
14 clat percentiles (msec):
15 | 1.00th=[ 55], 5.00th=[ 66], 10.00th=[ 73], 20.00th=[ 82],
16 | 30.00th=[ 88], 40.00th=[ 93], 50.00th=[ 99], 60.00th=[ 104],
17 | 70.00th=[ 110], 80.00th=[ 118], 90.00th=[ 131], 95.00th=[ 144],
18 | 99.00th=[ 4933], 99.50th=[ 5470], 99.90th=[ 6275], 99.95th=[ 6745],
19 | 99.99th=[15368]
20 bw ( KiB/s): min= 7, max= 544, per=30.98%, avg=218.10, stdev=177.46, samples=1458
21 iops : min= 1, max= 136, avg=54.44, stdev=44.36, samples=1458
22 write: IOPS=29, BW=118KiB/s (121kB/s)(104MiB/900008msec)
23 slat (usec): min=5, max=11845k, avg=12893.30, stdev=92058.77
24 clat (usec): min=6, max=15754k, avg=203521.09, stdev=710834.42
25 lat (msec): min=11, max=15754, avg=216.42, stdev=755.18
26 clat percentiles (msec):
27 | 1.00th=[ 55], 5.00th=[ 67], 10.00th=[ 74], 20.00th=[ 83],
28 | 30.00th=[ 88], 40.00th=[ 94], 50.00th=[ 100], 60.00th=[ 105],
29 | 70.00th=[ 111], 80.00th=[ 120], 90.00th=[ 132], 95.00th=[ 146],
30 | 99.00th=[ 4866], 99.50th=[ 5403], 99.90th=[ 6477], 99.95th=[ 6745],
31 | 99.99th=[13624]
32 bw ( KiB/s): min= 7, max= 392, per=34.45%, avg=161.90, stdev=115.63, samples=1310
33 iops : min= 1, max= 98, avg=40.38, stdev=28.91, samples=1310
34 lat (usec) : 10=0.01%
35 lat (msec) : 20=0.01%, 50=0.46%, 100=52.90%, 250=44.20%, 500=0.05%
36 lat (msec) : 750=0.03%, 1000=0.04%, 2000=0.14%, >=2000=2.17%
37 cpu : usr=0.06%, sys=0.93%, ctx=94550, majf=0, minf=10
38 IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=100.0%, 32=0.0%, >=64=0.0%
39 submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
40 complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.1%, 32=0.0%, 64=0.0%, >=64=0.0%
41 issued rwt: total=39782,26537,0, short=0,0,0, dropped=0,0,0
42 latency : target=0, window=0, percentile=100.00%, depth=16
43file1: (groupid=0, jobs=1): err= 0: pid=20618: Sat Feb 6 22:33:00 2021
44 read: IOPS=43, BW=175KiB/s (180kB/s)(154MiB/900004msec)
45 slat (usec): min=3, max=1121.0k, avg=14131.26, stdev=57098.32
46 clat (msec): min=8, max=17004, avg=201.05, stdev=724.28
47 lat (msec): min=10, max=17341, avg=215.18, stdev=770.32
48 clat percentiles (msec):
49 | 1.00th=[ 55], 5.00th=[ 67], 10.00th=[ 73], 20.00th=[ 82],
50 | 30.00th=[ 88], 40.00th=[ 93], 50.00th=[ 99], 60.00th=[ 104],
51 | 70.00th=[ 110], 80.00th=[ 118], 90.00th=[ 131], 95.00th=[ 146],
52 | 99.00th=[ 5000], 99.50th=[ 5604], 99.90th=[ 6745], 99.95th=[ 7282],
53 | 99.99th=[15368]
54 bw ( KiB/s): min= 8, max= 521, per=31.47%, avg=221.56, stdev=175.76, samples=1425
55 iops : min= 2, max= 130, avg=55.39, stdev=43.94, samples=1425
56 write: IOPS=29, BW=117KiB/s (120kB/s)(103MiB/900004msec)
57 slat (usec): min=5, max=11488k, avg=12939.67, stdev=90499.57
58 clat (usec): min=7, max=16864k, avg=210838.70, stdev=765745.75
59 lat (msec): min=8, max=17197, avg=223.78, stdev=810.75
60 clat percentiles (msec):
61 | 1.00th=[ 56], 5.00th=[ 68], 10.00th=[ 74], 20.00th=[ 83],
62 | 30.00th=[ 89], 40.00th=[ 94], 50.00th=[ 100], 60.00th=[ 106],
63 | 70.00th=[ 112], 80.00th=[ 121], 90.00th=[ 133], 95.00th=[ 148],
64 | 99.00th=[ 5134], 99.50th=[ 5738], 99.90th=[ 7215], 99.95th=[ 7752],
65 | 99.99th=[16442]
66 bw ( KiB/s): min= 8, max= 376, per=34.02%, avg=159.88, stdev=114.79, samples=1320
67 iops : min= 2, max= 94, avg=39.97, stdev=28.70, samples=1320
68 lat (usec) : 10=0.01%
69 lat (msec) : 10=0.01%, 20=0.01%, 50=0.47%, 100=52.07%, 250=45.09%
70 lat (msec) : 500=0.05%, 750=0.03%, 1000=0.03%, 2000=0.15%, >=2000=2.10%
71 cpu : usr=0.06%, sys=0.90%, ctx=94572, majf=0, minf=11
72 IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=100.0%, 32=0.0%, >=64=0.0%
73 submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
74 complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.1%, 32=0.0%, 64=0.0%, >=64=0.0%
75 issued rwt: total=39474,26387,0, short=0,0,0, dropped=0,0,0
76 latency : target=0, window=0, percentile=100.00%, depth=16
77file1: (groupid=0, jobs=1): err= 0: pid=20619: Sat Feb 6 22:33:00 2021
78 read: IOPS=44, BW=176KiB/s (181kB/s)(155MiB/900007msec)
79 slat (usec): min=3, max=11683k, avg=14867.35, stdev=82362.34
80 clat (msec): min=11, max=16858, avg=204.65, stdev=715.21
81 lat (msec): min=11, max=17187, avg=219.52, stdev=765.14
82 clat percentiles (msec):
83 | 1.00th=[ 54], 5.00th=[ 67], 10.00th=[ 73], 20.00th=[ 82],
84 | 30.00th=[ 88], 40.00th=[ 93], 50.00th=[ 99], 60.00th=[ 104],
85 | 70.00th=[ 111], 80.00th=[ 118], 90.00th=[ 132], 95.00th=[ 146],
86 | 99.00th=[ 4732], 99.50th=[ 5537], 99.90th=[ 6611], 99.95th=[ 6879],
87 | 99.99th=[14429]
88 bw ( KiB/s): min= 8, max= 520, per=30.48%, avg=214.60, stdev=177.32, samples=1479
89 iops : min= 2, max= 130, avg=53.65, stdev=44.33, samples=1479
90 write: IOPS=29, BW=117KiB/s (120kB/s)(103MiB/900007msec)
91 slat (usec): min=4, max=1052.3k, avg=11700.04, stdev=51144.23
92 clat (usec): min=7, max=16668k, avg=203458.32, stdev=725566.69
93 lat (msec): min=10, max=17344, avg=215.16, stdev=761.82
94 clat percentiles (msec):
95 | 1.00th=[ 56], 5.00th=[ 67], 10.00th=[ 73], 20.00th=[ 83],
96 | 30.00th=[ 88], 40.00th=[ 94], 50.00th=[ 100], 60.00th=[ 105],
97 | 70.00th=[ 111], 80.00th=[ 120], 90.00th=[ 132], 95.00th=[ 146],
98 | 99.00th=[ 4866], 99.50th=[ 5537], 99.90th=[ 6477], 99.95th=[ 6745],
99 | 99.99th=[16576]
100 bw ( KiB/s): min= 8, max= 400, per=33.97%, avg=159.68, stdev=115.75, samples=1324
101 iops : min= 2, max= 100, avg=39.92, stdev=28.94, samples=1324
102 lat (usec) : 10=0.01%
103 lat (msec) : 20=0.01%, 50=0.54%, 100=52.27%, 250=44.71%, 500=0.05%
104 lat (msec) : 750=0.04%, 1000=0.05%, 2000=0.15%, >=2000=2.20%
105 cpu : usr=0.06%, sys=1.03%, ctx=94387, majf=0, minf=11
106 IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=100.0%, 32=0.0%, >=64=0.0%
107 submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
108 complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.1%, 32=0.0%, 64=0.0%, >=64=0.0%
109 issued rwt: total=39683,26434,0, short=0,0,0, dropped=0,0,0
110 latency : target=0, window=0, percentile=100.00%, depth=16
111file1: (groupid=0, jobs=1): err= 0: pid=20620: Sat Feb 6 22:33:00 2021
112 read: IOPS=43, BW=176KiB/s (180kB/s)(154MiB/900003msec)
113 slat (usec): min=3, max=11508k, avg=14369.45, stdev=81491.16
114 clat (usec): min=7, max=17024k, avg=200537.92, stdev=722782.28
115 lat (msec): min=8, max=17349, avg=214.91, stdev=771.35
116 clat percentiles (msec):
117 | 1.00th=[ 55], 5.00th=[ 67], 10.00th=[ 73], 20.00th=[ 82],
118 | 30.00th=[ 88], 40.00th=[ 93], 50.00th=[ 99], 60.00th=[ 104],
119 | 70.00th=[ 110], 80.00th=[ 118], 90.00th=[ 131], 95.00th=[ 144],
120 | 99.00th=[ 4866], 99.50th=[ 5470], 99.90th=[ 6946], 99.95th=[ 7550],
121 | 99.99th=[16040]
122 bw ( KiB/s): min= 8, max= 561, per=30.93%, avg=217.76, stdev=176.59, samples=1452
123 iops : min= 2, max= 140, avg=54.44, stdev=44.15, samples=1452
124 write: IOPS=29, BW=118KiB/s (121kB/s)(104MiB/900003msec)
125 slat (usec): min=4, max=1116.2k, avg=12454.71, stdev=55514.46
126 clat (msec): min=19, max=16182, avg=209.52, stdev=735.52
127 lat (msec): min=19, max=16427, avg=221.97, stdev=775.08
128 clat percentiles (msec):
129 | 1.00th=[ 54], 5.00th=[ 67], 10.00th=[ 74], 20.00th=[ 82],
130 | 30.00th=[ 89], 40.00th=[ 94], 50.00th=[ 100], 60.00th=[ 105],
131 | 70.00th=[ 112], 80.00th=[ 120], 90.00th=[ 133], 95.00th=[ 148],
132 | 99.00th=[ 4933], 99.50th=[ 5604], 99.90th=[ 6812], 99.95th=[ 7483],
133 | 99.99th=[15234]
134 bw ( KiB/s): min= 8, max= 424, per=34.20%, avg=160.76, stdev=116.03, samples=1323
135 iops : min= 2, max= 106, avg=40.19, stdev=29.01, samples=1323
136 lat (usec) : 10=0.01%
137 lat (msec) : 10=0.01%, 20=0.01%, 50=0.45%, 100=52.41%, 250=44.69%
138 lat (msec) : 500=0.06%, 750=0.04%, 1000=0.05%, 2000=0.14%, >=2000=2.15%
139 cpu : usr=0.05%, sys=1.07%, ctx=94392, majf=0, minf=13
140 IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=100.0%, 32=0.0%, >=64=0.0%
141 submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
142 complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.1%, 32=0.0%, 64=0.0%, >=64=0.0%
143 issued rwt: total=39534,26590,0, short=0,0,0, dropped=0,0,0
144 latency : target=0, window=0, percentile=100.00%, depth=16
145
146Run status group 0 (all jobs):
147 READ: bw=704KiB/s (721kB/s), 175KiB/s-177KiB/s (180kB/s-181kB/s), io=619MiB (649MB), run=900003-900008msec
148 WRITE: bw=471KiB/s (482kB/s), 117KiB/s-118KiB/s (120kB/s-121kB/s), io=414MiB (434MB), run=900003-900008msec
Results
The workload of EFS looks like this, where the first part of the timeline is the General Purpose and the second one is the Max I/O.
(src="efs.png")
Now if we get the IOPS from both EFS types:
GP:
1Reads:
2iops : min= 1, max= 190, avg=81.21, stdev=64.04, samples=1626
3iops : min= 1, max= 202, avg=80.42, stdev=63.81, samples=1638
4iops : min= 2, max= 196, avg=80.80, stdev=63.86, samples=1633
5iops : min= 2, max= 188, avg=80.94, stdev=63.88, samples=1630
6
7Writes:
8
9iops : min= 1, max= 149, avg=54.91, stdev=42.52, samples=1596
10iops : min= 2, max= 134, avg=55.69, stdev=42.38, samples=1576
11iops : min= 2, max= 152, avg=55.88, stdev=42.60, samples=1580
12iops : min= 2, max= 142, avg=55.42, stdev=42.80, samples=1591
Max I/O:
1Reads:
2iops : min= 1, max= 136, avg=54.44, stdev=44.36, samples=1458
3iops : min= 2, max= 130, avg=55.39, stdev=43.94, samples=1425
4iops : min= 2, max= 130, avg=53.65, stdev=44.33, samples=1479
5iops : min= 2, max= 140, avg=54.44, stdev=44.15, samples=1452
6
7Writes:
8iops : min= 1, max= 98, avg=40.38, stdev=28.91, samples=1310
9iops : min= 2, max= 94, avg=39.97, stdev=28.70, samples=1320
10iops : min= 2, max= 100, avg=39.92, stdev=28.94, samples=1324
11iops : min= 2, max= 106, avg=40.19, stdev=29.01, samples=1323
I provisioned 4MB/s specifically because of 10GB with a provision of 4MB/s costs about 30$ p/m. Going higher in MB/s is quite expensive. I felt this was a "sane" value. Funny thing though, my more expensive setup was worse than my first run with just the General Purpose one.
Now I did invest some time to comprehend the EFS solution regarding hard & soft limits, pricing, various performance types, and the throughput. Yet honestly, I have no idea why this happened. My best bet is that the GP used a freebie on throughput.
If you take a look again at the previous screenshot, you can see that the GP was quite fast on uploading the 10GB file, while the Max I/O took a while (in line with 4MB/s):
Anyhow, if we look at EBS:
Reads:
1iops : min= 124, max= 1412, avg=562.72, stdev=403.76, samples=1800
2iops : min= 124, max= 1364, avg=565.18, stdev=405.62, samples=1800
3iops : min= 106, max= 1420, avg=563.72, stdev=404.78, samples=1800
4iops : min= 120, max= 1358, avg=564.59, stdev=406.06, samples=1800
5
6Writes:
7
8iops : min= 72, max= 906, avg=375.73, stdev=270.89, samples=1800
9iops : min= 84, max= 978, avg=378.11, stdev=272.58, samples=1800
10iops : min= 82, max= 902, avg=376.66, stdev=270.12, samples=1800
11iops : min= 62, max= 908, avg=376.69, stdev=269.78, samples=1800
These are just sane values we can work with for most use-cases. Perhaps we have to buff EBS a bit more (which is possible) for higher performance, but the base-line is solid.
Stability
The thing the tests did not show was stability on the performance and how the systems deals with its storage. To give you an example, if I would run the read/write test and try to do something on the file system, it either locks out or is terrible slow.
1root@ip-172-31-16-158:/efs# time ls -lah
2total 11G
3drwxr-xr-x 2 root root 6.0K Feb 6 21:07 .
4drwxr-xr-x 25 root root 4.0K Feb 6 20:15 ..
5-rw-r--r-- 1 root root 10G Feb 6 21:19 fio-rand-RW
6
7real 0m11.318s
8user 0m0.000s
9sys 0m0.036s
Yes, that took 11.3 seconds.
Also, a funny thing, when I placed the 10GB file and did a list in my folder, it took the time of uploading the file (about 30-40 minutes) before my list command was completed.
Obviously, I'm here "abusing" EFS, but I really wanted to show you why it's not suitable for applications.
Use-cases for EFS
So it does have use-cases, for instance in a CMS to include documents and other files. I guess various SAP solutions can use it. It can be really good on that. It just scales with how much data you have on it and you can provision throughput based on what you want. It allows for many hosts to mount the volume and has quite some read/write power. Roughly 35.000 actions per second.
Yet this is just not great for workloads you expect on Kubernetes. If EBS is not an option and S3 is not supported, I assume you can go for EFS if your workload does not go mental on it. I.e. if you store artifacts on it, fine. If you use it to process data ON EFS, I would say: nope.
EFS is a can of worms though.
When I was fiddling around, I felt I have to address this. I'm just going to post some quotes from the AWS website.
Amazon EFS offers a Standard and an Infrequent Access storage class. The Standard storage class is designed for active file system workloads and you pay only for the file system storage you use per month.
Enable Lifecycle Management when your file system contains files that are not accessed every day to reduce your storage costs
Files smaller than 128 KiB are not eligible for Lifecycle Management and will always be stored on Amazon EFS Standard storage class.
When reading from or writing to Amazon EFS IA, your first-byte latency is higher than that of Amazon EFS Standard.
Throughput of bursting mode file systems scales linearly with the amount of data stored. If you need more throughput than you can achieve with your amount of data stored, you can configure Provisioned Throughput.
EFS supports one to thousands of Amazon EC2 instances connecting to a file system concurrently
Amazon EFS’s distributed design avoids the bottlenecks and constraints inherent to traditional file servers
This distributed data storage design means that multi-threaded applications, and applications that concurrently access data from multiple Amazon EC2 instances can drive substantial levels of aggregate throughput and IOPS
Due to this per-operation latency, overall throughput generally increases as the average I/O size increases, since the overhead is amortized over a larger amount of data
“Max I/O” performance mode is optimized for applications where tens, hundreds, or thousands of EC2 instances are accessing the file system
With bursting mode, the default throughput mode for Amazon EFS file systems, the throughput available to a file system scales as a file system grows.
Also, because many workloads are read-heavy, read operations are metered at a 1:3 ratio to other NFS operations (like write).
All file systems deliver a consistent baseline performance of 50 MB/s per TB of Standard class storage
All file systems (regardless of size) can burst to 100 MB/s,
File systems with more than 1TB of Standard class storage can burst to 100 MB/s per TB
Since read operations are metered at a 1:3 ratio, you can drive up to 300 MiBs/s per TiB of read throughput.
Provisioned Throughput also includes 50 KB/s per GB (or 1 MB/s per 20 GB) of throughput in the price of Standard storage.
and there are more...

Look, I get it. Storage is hard. AWS tries to give options to users but also requires $$$ depending on what your requirements are. The problem is however, it's getting too many variables. It's getting hard to understand what is happening, why that's happening, and how much that will cost you.
So don't get me wrong, I do think AWS made something really awesome with EFS (if you use it correctly) but its setup and billing model is an abomination.
Furthermore, I see quite some statements regarding IOPS and throughput but the reality is different depending on your use-case. The test I did with random read/writes gave about 50 IOPS for both reads and writes on average. So, 100 IOPS to make it easier. AWS states:
"In General Purpose mode, there is a limit of 35,000 file operations per second. Operations that read data or metadata consume one file operation, operations that write data or update metadata consume five file operations."
Talking about that can of worms again, but let's continue:
"This means that a file system can support 35,000 read operations per second, or 7,000 write operations, or some combination of the two. For example, 20,000 read operations and 3,000 write operations (20,000 reads x 1 file operation per read + 3,000 writes x 5 file operations per write = 35,000 file operations)."
Well, that was not really in line with my test. So after searching and searching I could not find exact numbers on IOPS and how this was calculated. Then I found this slide:
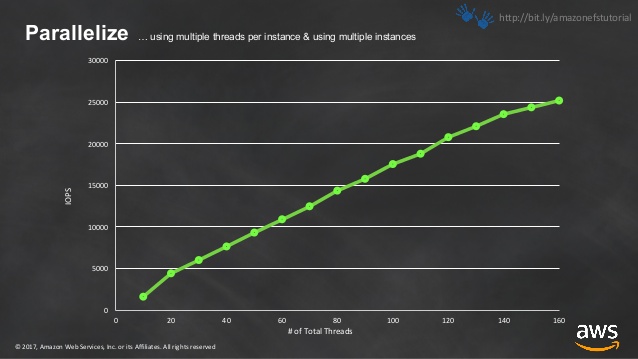
So I believe these "35,000" file operations are based on concurrency. Multiple hosts asking for "some file". Often this is not the case. Therefore I believe the base-line IOPS for EFS is 100.
What if you want good storage for multi-AZ?
Now we know that EFS is not a solid option, unless we change the behavior of our application, we can think about a solution for having EBS-like storage but for multi-AZ.
The fact is, there is not an AWS solution for this. No storage option does not focus on RWX type of "file sharing" but rather plain cool EBS that can be mounted in every AZ.
If you do not want the trade-off that I discussed before, there is only one other solution and that is creating your own storage stack :)
My two favorites are:
Longhorn: https://github.com/longhorn/longhorn and Rook/Ceph: https://github.com/rook/rook
It's enterprise-grade distributed storage with no single point of failure, cloud-native and it's distributed in a way that it's like EBS, without the zone limitation.
Now, this does add complexity and something you have to manage. Yet if you want to run your clusters on 3 AZ's, have workloads that can use simple block storage for processing, and/or don't want to run inefficiently on Kubernetes: This might be just it.
Perhaps in a follow-up, I'll do a deeper dive into these solutions.
Recap
- EFS is good as a product but only suitable for certain workloads and requires A LOT of thought on how you want to use it
- S3 is not a file system, but an excellent way to store "media", backups, data-lake, etc.
- EBS is solid for storage; boot volumes, whatever database (I'm not saying you should run databases on k8s though)
If you have certain requirements, be sure that the storage you pick can support that. Also, make sure you keep your requirements in line. Don't abuse storage for your requirements. If you need RWX volumes and EFS is your only option, perhaps consider rewriting your application to modern standards.
Multi-zone mounts are not supported by EBS, which is really unfortunate.
My take on EBS multi-zone support
I believe AWS makes a lot of money on EFS. Legacy applications need to use it if they are pushed into the cloud (I'm watching you SAP). EFS does have legit use-cases but I strongly believe it's often used because there is no alternative and the only solution to make something work. Therefore the incentive to make something like EBS for multi-zones is gone.
0,30$ per GB stored and 6$ per MB/s provisioned per month is also no incentive to create something else.
For reference, EBS costs $0.08/GB-month, 125 MB/s free and $0.04/provisioned MB/s-month over 125. That includes the up to 3,000 IOPS standard.