Multiple Kubernetes cluster monitoring with Prometheus
If you have multiple Kubernetes clusters, there are a few ways to implement monitoring with Prometheus. Generally speaking, when using the Prometheus operator, it will assume it's running in its current cluster. Now we still have two variations. Because are we talking about "querying data over multiple clusters" or "having the data from multiple clusters in one cluster"? For example, it's possible to have a Prometheus instance in each cluster and one central Prometheus to gather it all. Or we can scrape all the clusters with one single central Prometheus.
Disclaimer
I'm actually a team member of Thanos: https://thanos.io/ - However I don't have any (financial) gains to be made here. Unlike some other tooling that merely make it to promote their product with weird comparisons. Cough It starts with a V and ends with ictoria. Cough. So at some point I show a few options wich includes Thanos. I only do this because I'm familiair with Thanos. There are alternatives such as:
- Cortex: https://cortexmetrics.io/
and there are a lot of solutions which allow for remote write, which include but not limited:
- Grafana cloud: https://grafana.com/products/cloud/
- New relic: https://docs.newrelic.com/docs/integrations/prometheus-integrations/install-configure-remote-write/set-your-prometheus-remote-write-integration/
Again, I wrote this blog to give people options and share my knowledge. So, without further ado, let's start with option 1;
One cluster with Prometheus to scrape multiple clusters
For this, I would just simply refer to the documentation of Prometheus itself. More specifically the kubernetes_sd_config: https://prometheus.io/docs/prometheus/latest/configuration/configuration/#kubernetes_sd_config
1# The API server addresses. If left empty, Prometheus is assumed to run inside
2# of the cluster and will discover API servers automatically and use the pod's
3# CA certificate and bearer token file at /var/run/secrets/kubernetes.io/serviceaccount/.
4[ api_server: <host> ]
The short story here is that we auth ourself (again, various options) with an external cluster and based on your configuration you can discover services, nodes, pods and ingresses. Depending on further configuration, you can apply any other 'rules' as you would do in your own cluster. Normally the Prometheus operator has already done that for you.
My personal opinion on the pro's and con's:
Pro's:
- Does not require Prometheus running in 'the external' cluster.
- Somewhat easy to implement if you know how things actually work :)
Neutral:
- You should probably think about how to deal with all the data when running many clusters.
Con's
- It can be a bit hard to master to know exactly how things work and how you want things to happen.
- Cross-cluster authentication, which might be really annoying.
One cluster with Prometheus using federation to scrape other clusters
Honestly, I'm only writing this because it is an option. Thought I really find this not a real solution. Obviously I'm biased with my experiences and this might work perfectly fine for you.
With Federation (https://prometheus.io/docs/prometheus/latest/federation/#hierarchical-federation) you will need:
- Each cluster to run their own Prometheus stack/instance.
- One 'observer' cluster with a Prometheus that has configured each Prometheus as federation endpoint.
As per example on the Prometheus website:
1scrape_configs:
2 - job_name: 'federate'
3 scrape_interval: 15s
4
5 honor_labels: true
6 metrics_path: '/federate'
7
8 params:
9 'match[]':
10 - '{job="prometheus"}'
11 - '{__name__=~"job:.*"}'
12
13 static_configs:
14 - targets:
15 - 'source-prometheus-1:9090'
16 - 'source-prometheus-2:9090'
17 - 'source-prometheus-3:9090'
This means data is actually duplicated and we are now just scraping the external Prometheus for all its data.
Pro's
- Really easy to implement as this only requires the Prometheus to be scrapable by your observer cluster
Neutral
- Requires Prometheus per cluster
Con's
- Even when you 'only' have the default metrics that come with the Prometheus Operator, the amount of data scraped is massive. I have experienced 80MiB of data per scrape which took 30+ seconds to gather.
- You could probably change the behaviour to not scrape "everything" via one job. Yet make multiple jobs and change the params on what
__name__(or anything else) to scrape per job.
- You could probably change the behaviour to not scrape "everything" via one job. Yet make multiple jobs and change the params on what
- Data is first scraped at the external cluster, and scraped again via the central cluster. If your scrape interval is 30s, you will have your data at most at 60s.
One cluster with Prometheus using exposes metric endpoints in other clusters
As long as Prometheus can reach a metric endpoint, it can scrape it. So if you only have a few endpoints you need to scrape (which is 99.9% of the time not the case), you could just simply expose your /metric endpoints via an ingress or whatever option you want.
Pro's
- Again, really easy to do
Con's
- Only useful when having limited amount of endpoints
- No autodiscovery
- No form of automation
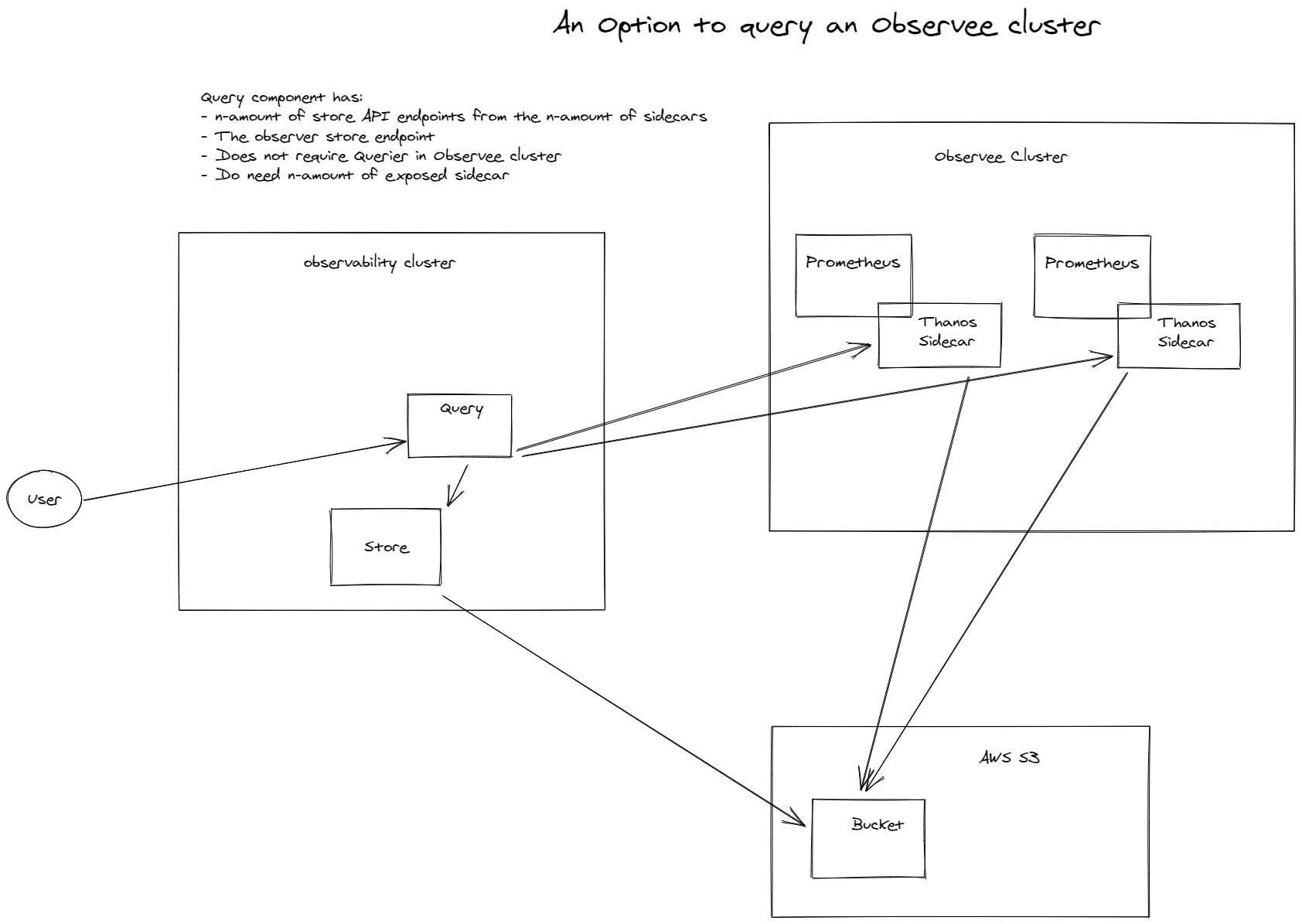
On cluster with Thanos Querier and Thanos sidecars in other clusters
With this setup we leverage Thanos. We implement a sidecar at the external clusters. Now we can have a querier at our observer cluster and set each sidecar as store. It will look like this:
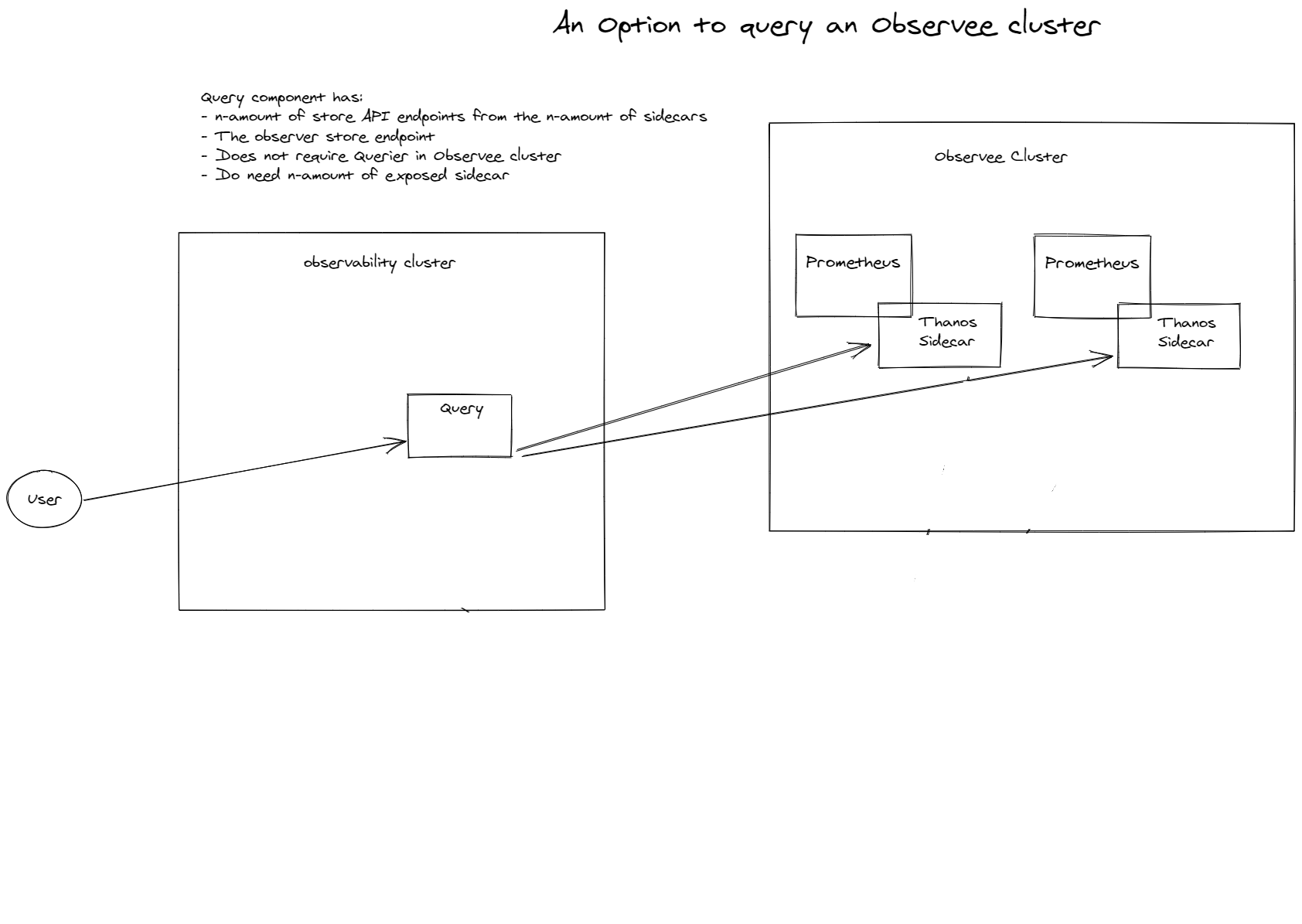
As you can see, there is also an S3 bucket. This is for long term storage, which is optional and not required.
Pro's
- Allows you to hook in external clusters and be able to query them
- Data stays at the external cluster, we merely extended the "query capabilities"
- Instantly works for Highly available setups as Thanos Query can deduplicate data
- Allows to ignore the observer cluster, and be able to still query on the external cluster
Con's / Neutral
- Does require extra components. You could see this as a con or neutral, depending on how you look at the value it creates
On cluster with Thanos Querier and Thanos sidecars and query in other clusters
This option is nearly the same as above. Yet rather than using the sidecars in our observee cluster, we add a Thanos Query component in each external cluster. This makes it easier to just place an ingress on your query component. This then can be just implemented highly available with a loadbalancer.
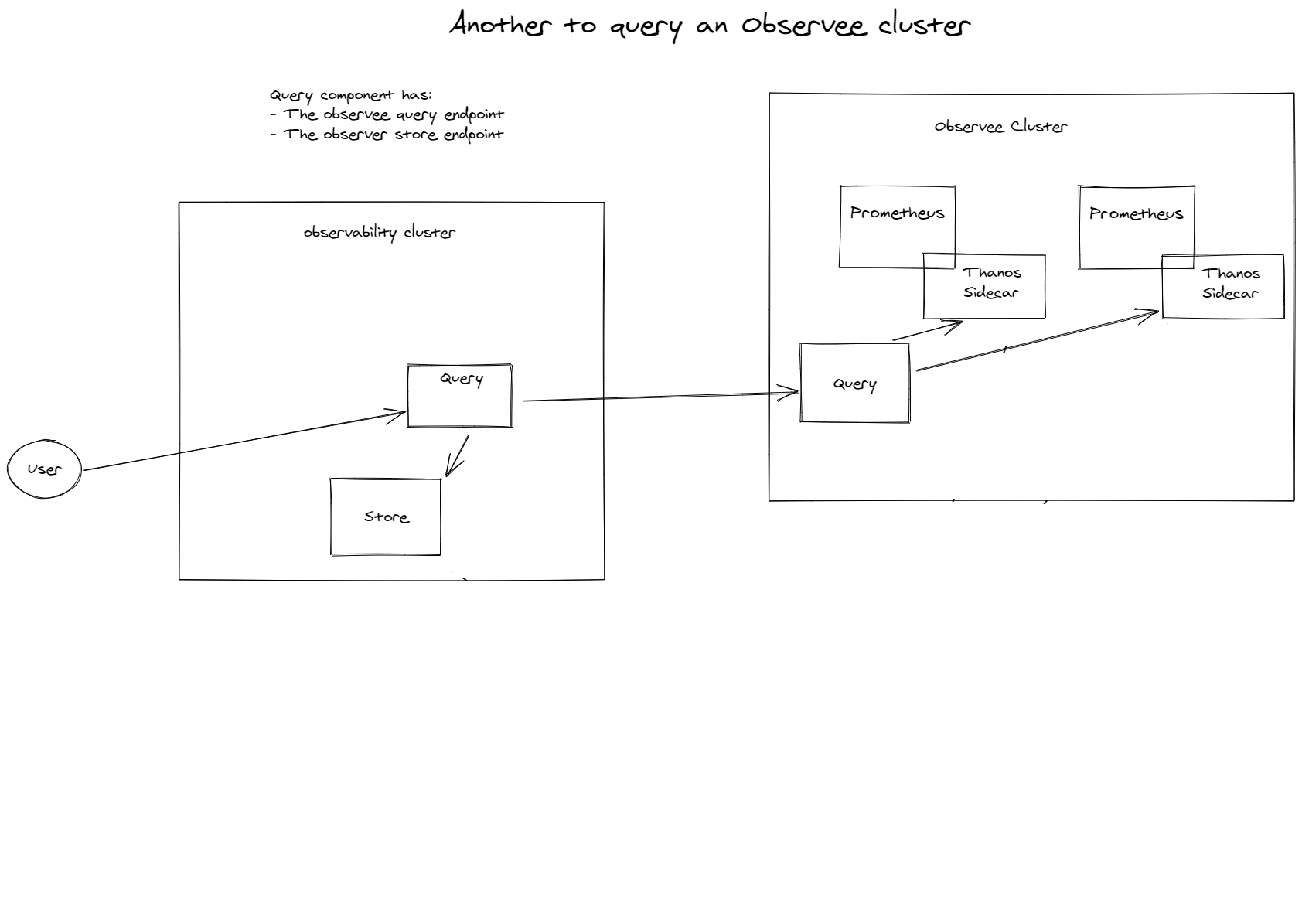
I'm not going over the pro's and con's here again, the mere difference is how you 'chain' everything together.
External clusters use remote-write
We have discussed pull-based options, but its also possible to push metrics. This option is quite useful when its hard or impossible to allow externals to 'enter' your cluster. At that point, you could just simply sent your data.
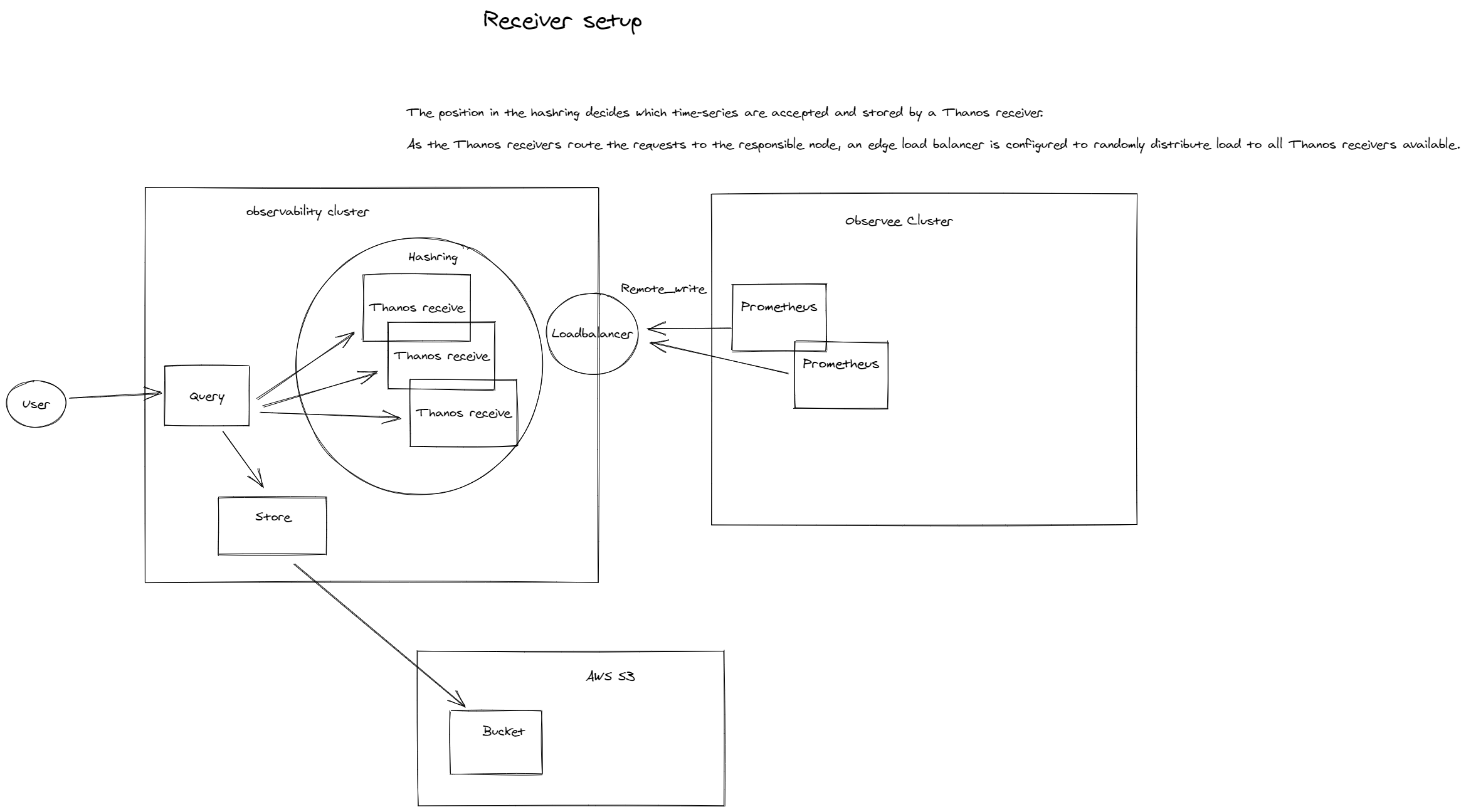
In this example I have used Thanos recievers for this capability. However Prometheus just has a generic remote write feature. There is a complete list of possible options. However do check if the option actually works for your use-case: https://prometheus.io/docs/operating/integrations/#remote-endpoints-and-storage
Pro's
- The best (and perhaps the only) option if you are unable to pull metrics.
- Requires less "state" on your external clusters. You only have to configure to push data out.
Con's
- I do believe it adds a bit more technical requirements. I think the learning curve is a bit higher than any other option.
- Removes the
upmetric as data is pushed.
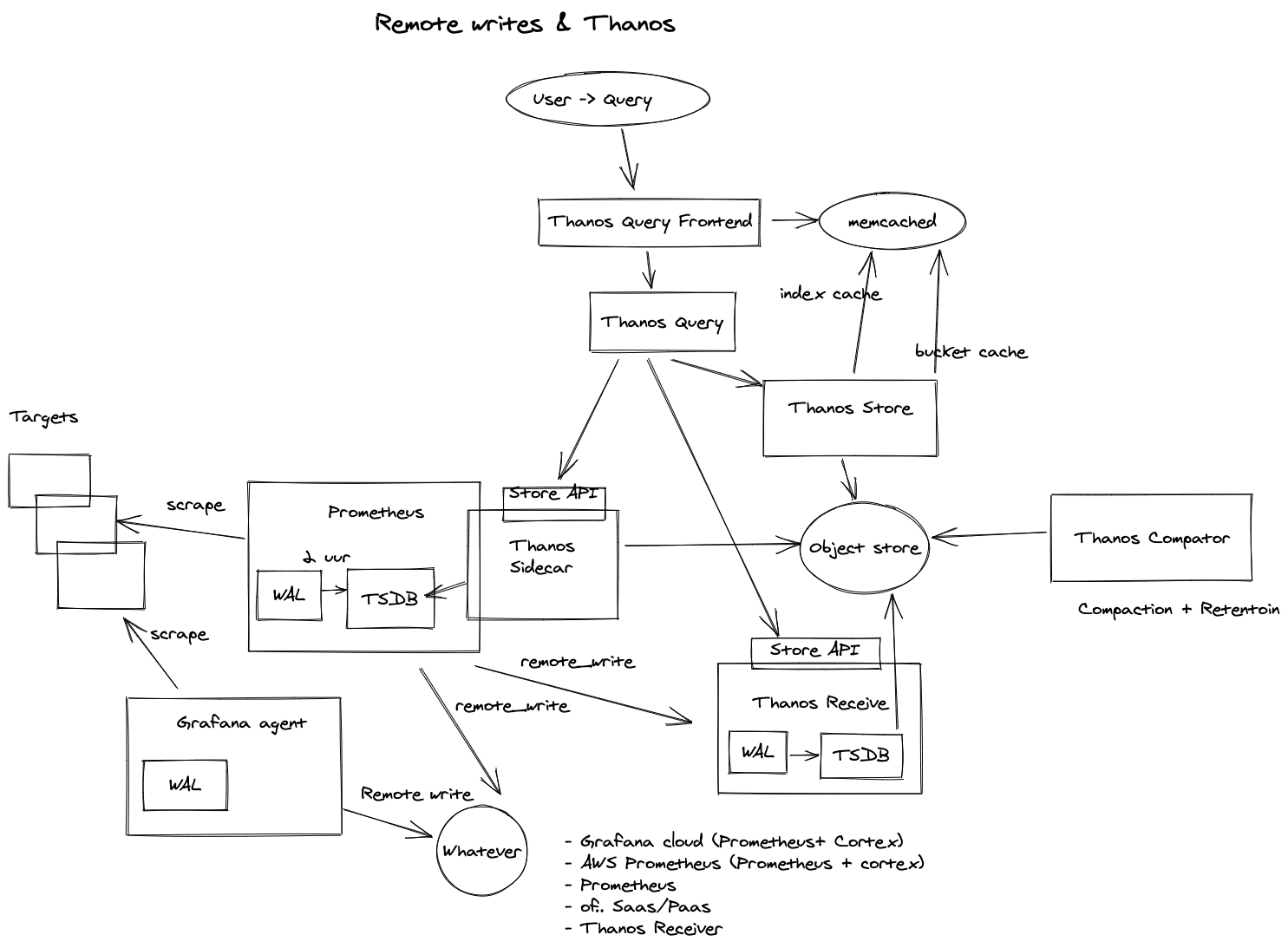
Using Thanos but with long term storage
I'm going to place this option as we should think about long term vision about your metrics. What I personally like about Thanos is the way we can store data. We can limit the rentention time on our Prometheuses and 'push' our data to an object store like S3.
It looks like this:
What happens is that Prometheus prepares it blocks and every 2 hours, these get uploaded to S3. With the Thanos Store component we now can query this data on S3. For data < 2 hours, we still use a Query or Sidecar endpoint to get those metrics.
The advantage is that we can leverage Thanos to have highly available, pluggable and long term storage metrics. With the option to chain every component in such way that we can have a central 'observee' cluster.
General tips you should think about
- Where are you going to store the data?
- Is this per cluster or in a central place?
- Have you thought about multi-tenancy? Certain options are better for this than others.
- Are you going to need long term storage?
- Do you still want to be able to 'directly query' on a cluster, rather than via a central point?
- How many clusters are we talking about? Some solutions require more thought about the amount of data. Which means you have to start sharding or split data differently.
In the end there are a lot of options you can implement. There are however also many solutions that allow to be chained / plugged, which makes it really neat to "do whatever you want".
To end this post, I've drawn another example of a few posibilities you could do with remote write!